June 1, 2026
Architecting AI Agent Motion Video Pipeline
A technical deep dive into overcoming microVM network starvation, Out-Of-Memory (OOM) orchestrator crashes, and high cold-boot penalties while building an autonomous AI agent that generates and renders 60fps cinematic motion videos entirely in the cloud.
Building an AI agent that can write code is one thing. Building an autonomous pipeline that takes that generated code, spins up an isolated cloud sandbox, renders a headless 60fps motion video, and delivers it to a user in seconds without crashing your servers—that is an entirely different engineering challenge.
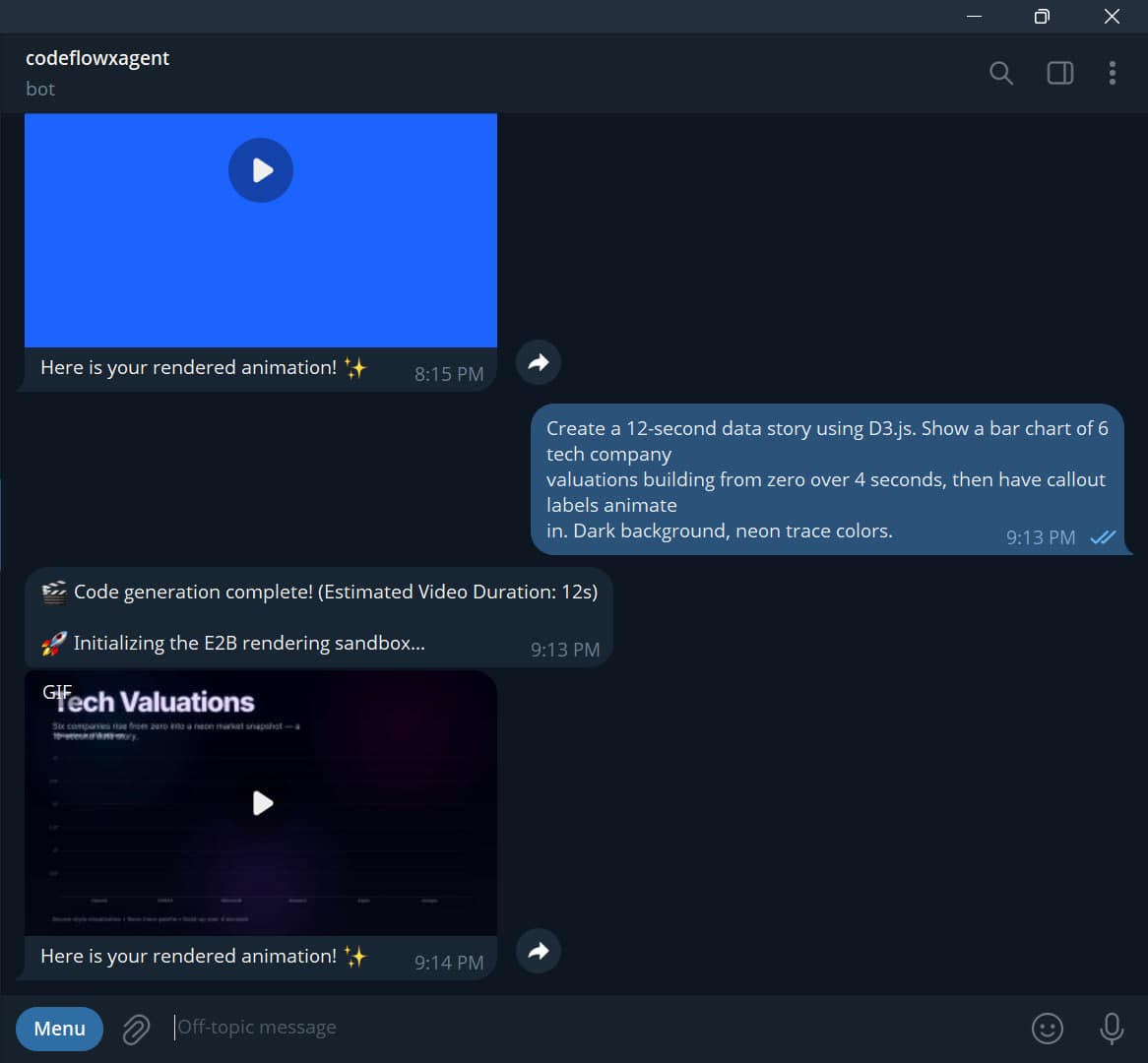
Recently, I set out to build an autonomous AI agent capable of programmatic motion graphics. The user messages a Telegram bot, the AI agent writes raw HTML/CSS/JS using professional animation libraries (like GSAP), and the system mathematically scrubs through the animation frame-by-frame to deliver a fluid, cinematic .mp4 motion video. While the concept sounds straightforward, executing it securely at scale required solving several severe infrastructural bottlenecks.
Here is a deep dive into the architecture and how I engineered my way out of strict microVM constraints and memory limits.
The Architecture Stack
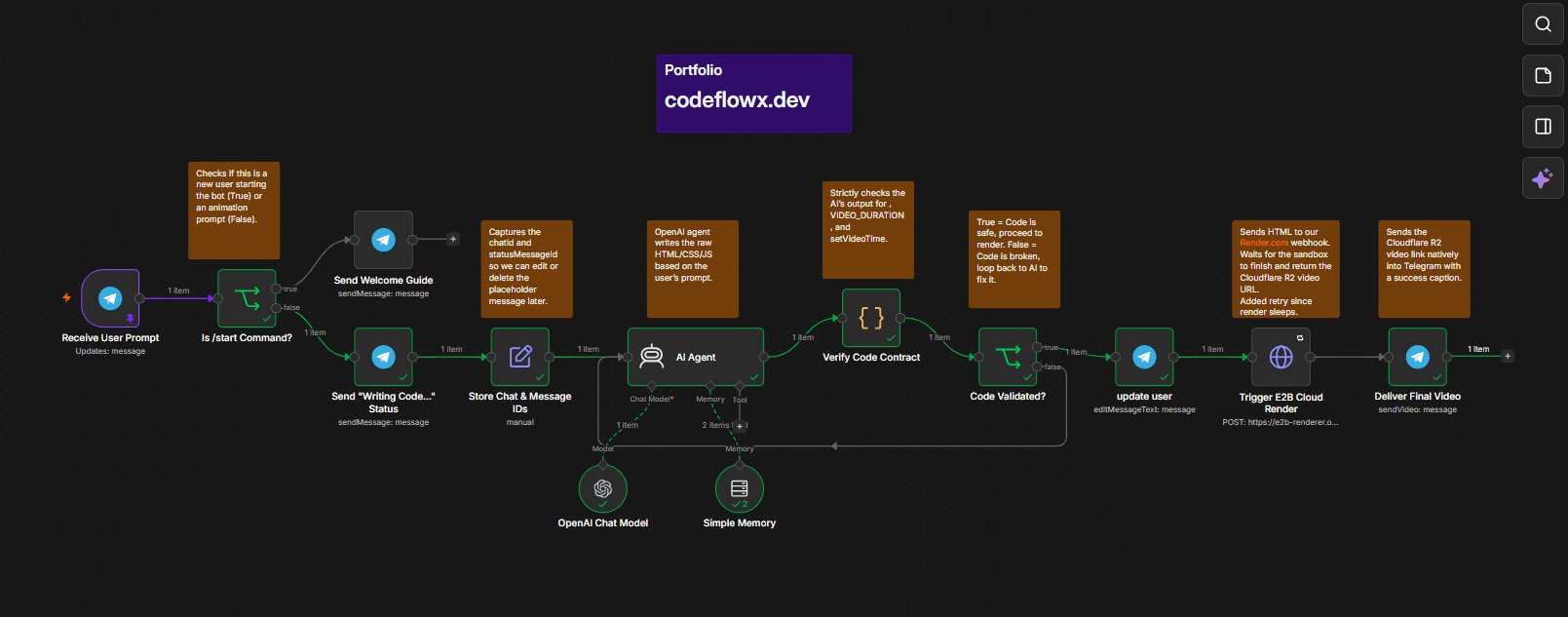
To orchestrate this autonomous AI agent, I relied on four main pillars:
n8n: The orchestration layer handling webhooks, state management, and the core AI agent routing.
Render.com Node.js Server: A custom-built, lightweight webhook bridging the AI agent and the cloud sandboxes.
E2B (Firecracker MicroVMs): Ephemeral, highly secure cloud sandboxes to execute the untrusted, AI-generated motion code and run the headless browser.
Cloudflare R2: S3-compatible edge storage with zero egress fees for final video delivery.
Challenge 1: MicroVM Resource Starvation
Running a headless browser to capture frame-perfect motion graphics inside a constrained micro-virtual machine is notoriously unstable. Initially, wrapping Chromium with standard Puppeteer libraries caused instant ProtocolError: Network.enable timed out deadlocks. Why? Because modern Chromium spawns dozens of background networking and telemetry threads that instantly choked the microVM's limited CPU, starving the primary DevTools protocol handshake.
The Solution: I abandoned standard Puppeteer launch wrappers. Instead, I manually executed the raw Chromium binary using Node's child_process.spawn(). By injecting over 25 aggressive flags—such as --disable-background-networking, --disable-dev-shm-usage, and --renderer-process-limit=1—I forced Chromium into an ultra-lightweight, single-process state perfectly tailored for rendering the AI agent's motion frames in constrained cloud sandboxes.
Challenge 2: Cold-Boot Penalties & Compute Waste
My initial render script dynamically installed Linux dependencies (apt-get install ffmpeg libnss3) and npm packages on every single request. This approach carried a massive 45-to-60-second cold-boot penalty, heavily degrading the user experience and burning through cloud compute credits before the AI agent could even capture a single frame of video.
The Solution: I authored a custom Docker template. By baking Chromium, FFmpeg, Puppeteer-core, and all necessary shared Linux graphics libraries into a master image, I reduced the sandbox boot time to milliseconds. The environment now spins up fully equipped and ready to render high-fidelity motion graphics the moment the AI agent finishes writing the code.
Challenge 3: Overcoming Out-of-Memory (OOM) Orchestrator Crashes
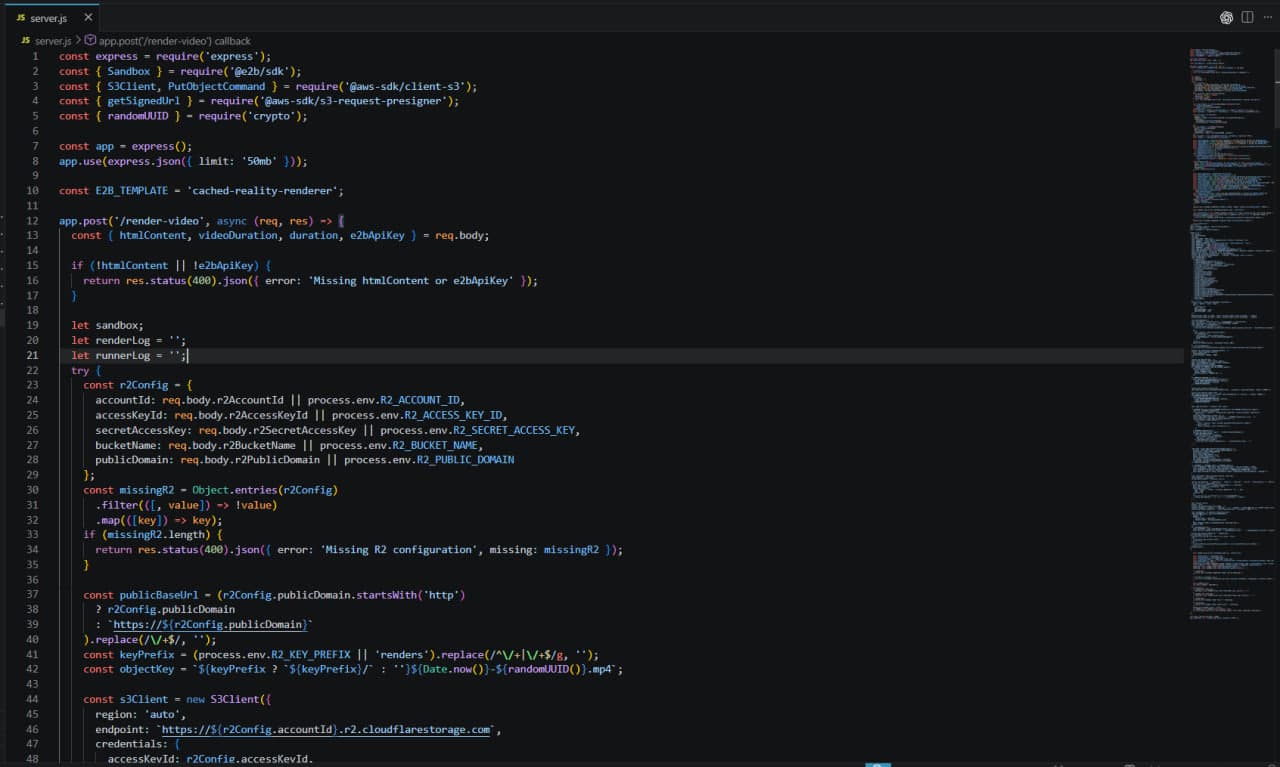
The most critical failure point of the early architecture was data transfer. Originally, the E2B sandbox generated the motion .mp4, passed the raw binary back to the Node.js bridge, which then forwarded it to n8n as an HTTP response. Holding 50MB+ of 60fps binary video data in active memory for concurrent requests inevitably triggered Out-Of-Memory (OOM) crashes in the n8n orchestrator.
The Solution: A Stateless File Transfer Architecture. I completely decoupled file storage from the orchestration logic by integrating Cloudflare R2.
The Node.js bridge generates a temporary, secure Pre-signed Upload URL.
It passes this "upload ticket" to the E2B sandbox.
The sandbox records the motion frames, encodes the video via
ffmpeg, and utilizes native Node.js streams (Readable.toWeb) to upload the binary directly to Cloudflare's edge storage.
My orchestration servers (both Render and n8n) now endure zero file-transfer overhead. The server simply returns a lightweight public URL string to the AI agent's n8n workflow, which is piped directly into the Telegram API for seamless inline playback.
Final Thoughts
By shifting to custom pre-built environments, implementing direct-to-cloud storage streams, and strictly managing headless browser memory, I transformed a highly fragile, compute-heavy concept into a robust, scalable, enterprise-grade autonomous AI agent.